工作总结
幂等
幂等性指对同一资源的多次请求与一次请求在业务效果上保持一致,强调“副作用只发生一次”。
说人话:同样的参数调用接口N次,结果跟调用一次是一样的。
举个栗子:用户手抖连续点了三次下单,系统只能生成一个订单,不能出三个。
前端可做的有限防护 : 按钮点击后置灰、表单防重复提交、进入页面先申请一次性token。这些手段能减少普通用户误操作,但无法阻止恶意重放或绕过前端,因此必须配合后端校验共同生效.
后端通用幂等框架与关键步骤 :
核心三步:为每次变更请求生成唯一请求ID(如业务流水号);处理前先“查重/占位”;首次处理成功后“写结果/标记状态”。
常见实现:
- 唯一索引/去重表:以业务唯一键(如订单号、流水号)建唯一索引,重复插入直接失败;或先插入“请求记录/防重表”,成功后再处理业务,失败则幂等返回。
- Token机制:进入页面获取token并存入Redis(设置TTL);提交时携带token,服务端以原子操作校验并删除token,通过则处理,否则判重。
- 状态机:仅允许按预设路径单向迁移(如“待支付→支付中→已支付/失败”),更新时以“当前状态=期望状态”为条件,天然阻断重复推进。
- 乐观锁:给业务表加version字段,更新时带上版本号,条件匹配才更新并自增版本,否则重试或报错。
- 分布式锁:以业务唯一键为锁key,用 Redis SET key value EX 30 NX获取锁,处理完成后释放;注意锁粒度、超时与异常释放,避免死锁与误删。
- 单机并发控制:同一JVM内可用 **
synchronized/ReentrantLock**,但仅限单机,分布式场景需用分布式锁替代
方案一:Token令牌法(推荐)
// 前端先要个token
@GetMapping("/token")
public String getToken() {
String token = UUID.randomUUID().toString();
redisTemplate.opsForValue().set(token, "1", 5, TimeUnit.MINUTES);
return token;
}
// 带着token请求
@PostMapping("/createOrder")
public Result createOrder(@RequestParam String token, Order order) {
// 原子性删除,保证只能用一次
Long result = redisTemplate.execute(
new DefaultRedisScript<>("if redis.call('get', KEYS[1]) then return redis.call('del', KEYS[1]) else return 0 end", Long.class),
Collections.singletonList(token)
);
if (result == 0) {
return Result.error("请勿重复提交");
}
// 正经业务逻辑
return orderService.create(order);
}
适用:表单提交、前端操作
方案二:数据库唯一索引(简单粗暴)
// 订单表加唯一索引
ALTER TABLE `order` ADD UNIQUE KEY `uk_order_no` (`order_no`);
// 代码里直接try-catch
public void createOrder(Order order) {
try {
orderMapper.insert(order);
} catch (DuplicateKeyException e) {
log.warn("订单已存在:{}", order.getOrderNo());
// 直接返回成功,或者查询已存在的订单
}
}
适用:订单号、流水号去重
方案三:乐观锁(更新操作必备)
// 商品表加个version字段
UPDATE product
SET stock = stock - #{quantity},
version = version + 1
WHERE id = #{productId}
AND version = #{oldVersion}
// 检查影响行数
int rows = productMapper.updateStock(params);
if (rows == 0) {
throw new BusinessException("库存扣减失败,请重试");
}
适用:库存扣减、账户余额更新
方案四:分布式锁(高并发必备)
public Result createSeckillOrder(OrderDTO orderDTO) {
String lockKey = "seckill:" + orderDTO.getGoodsId();
String clientId = UUID.randomUUID().toString();
try {
// 加锁,设置过期时间
Boolean result = redisTemplate.opsForValue()
.setIfAbsent(lockKey, clientId, 10, TimeUnit.SECONDS);
if (!Boolean.TRUE.equals(result)) {
return Result.error("抢购进行中,请稍后");
}
// 业务处理
return seckillService.createOrder(orderDTO);
} finally {
// 只能删除自己的锁
if (clientId.equals(redisTemplate.opsForValue().get(lockKey))) {
redisTemplate.delete(lockKey);
}
}
}
适用:秒杀、高并发场景
经验总结:
- 简单业务用唯一索引,省心
- 前端交互用Token,体验好
- 更新操作加乐观锁,必须的
- 高并发上分布式锁,稳如老狗
⚠️ 避坑提醒:
- Token一定要先获取再使用
- 分布式锁一定要设置超时时间
- 乐观锁一定要校验更新结果
- 所有方案都要考虑异常情况
这几种方案都是经过线上考验的,根据业务场景选就行。
CPU 100% 问题怎么排查?
ThreadLocal
syncronized
syncronized 使用对象锁保证临界区内代码的原子性。
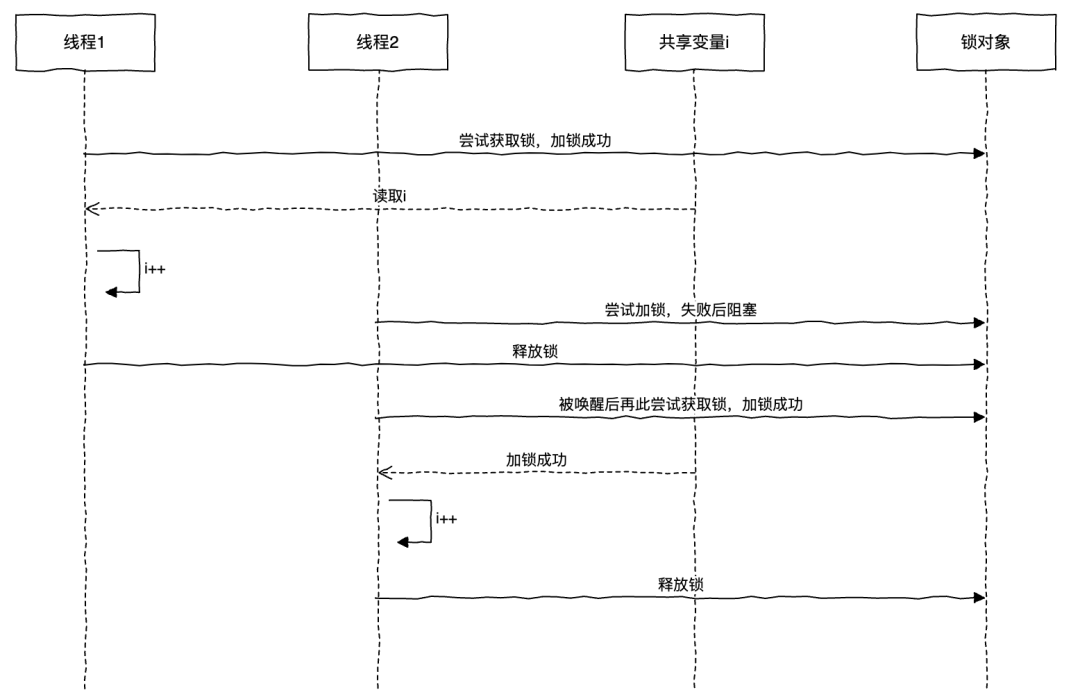
其实 synchronized 的原理也不难,主要有以下两个关键点。
- synchronized 又被称为监视器锁,基于 Monitor 机制实现的,主要依赖底层操作系统的互斥原语 Mutex(互斥量)。Monitor 类比加了锁的房间,一次只能有一个线程进入,进入房间即持有 Monitor,退出后就释放 Monitor。
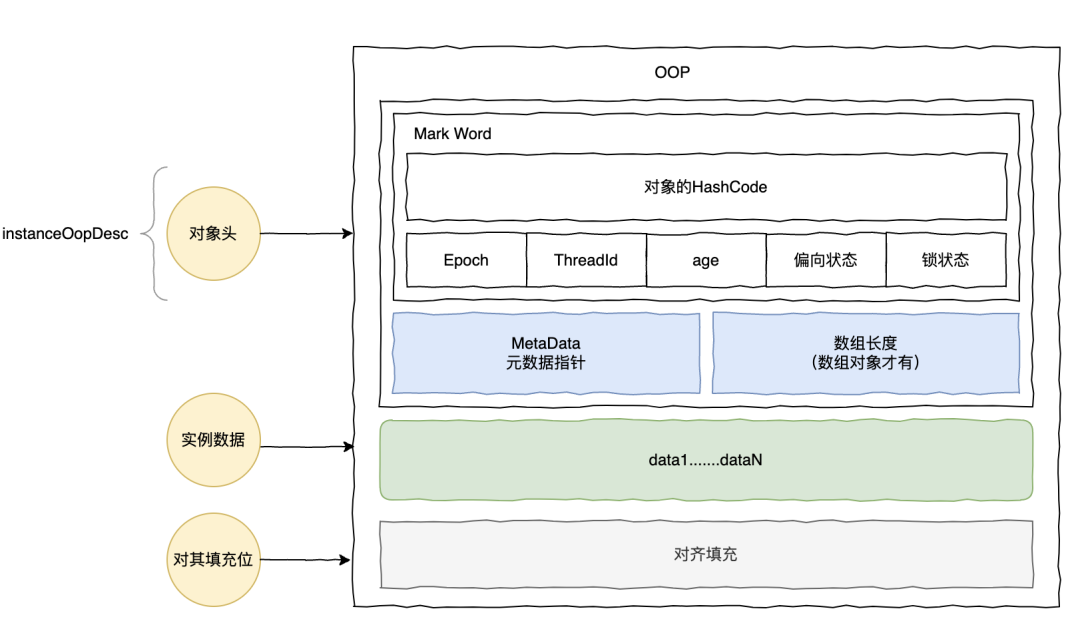
- 另一个关键点是 Java 对象头,在 JVM 虚拟机中,对象在内存中的存储结构有三部分:对象头;实例数据;对齐填充。
对象头主要包括标记字段 Mark World,元数据指针,如果是数组对象的话,对象头还必须存储数组长度。
这里,又引申另外出一个问题:你知道什么是偏向锁呢?
synchronized 锁升级过程
说到这里,那就不得不提及 synchronized 的锁升级机制了,因为 synchronized 的加锁释放锁操作会使得 CPU 在内核态和用户态之间发生切换,有一定性能开销。在 JDK1.5 版本以后,对 synchronized 做了锁升级的优化,主要利用轻量级锁、偏向锁、自适应锁等减少锁操作带来的开销,对其性能做了很大提升。
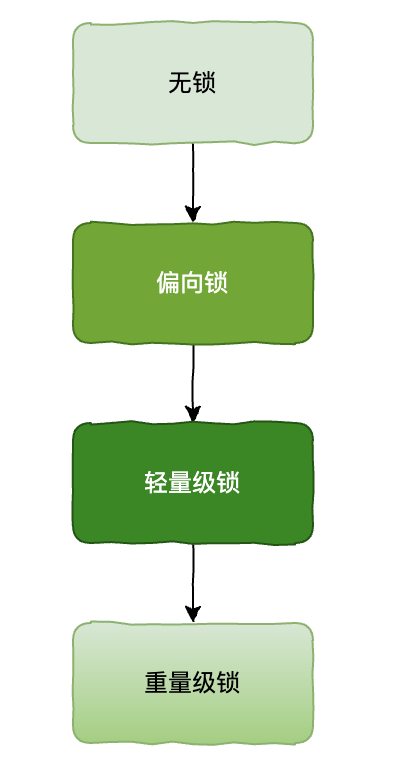
- 无锁:没有对资源进行加锁
- 偏向锁:在大部分情况下,只有一个线程访问修改资源,该线程自动获取锁,降低了锁操作的代价,这里就通过对象头的
ThreadId记录线程 ID。 - 轻量级锁:当前持有偏向锁,当有另外的线程来访问后,偏向锁会升级为轻量级锁,别的线程通过自旋形式尝试获取锁,不会阻塞,以提高性能。
- 重量级锁:在自旋次数或时间超过一定阈值时,最后会升级为重量级锁。
Java 除了隐式锁之外,还有显示锁呢?
ReentrantLock
在 Java 中,除了对象锁,还有显示的加锁的方式,比如 Lock 接口,用得比较多的就是 ReentrantLock。它的特性如下:
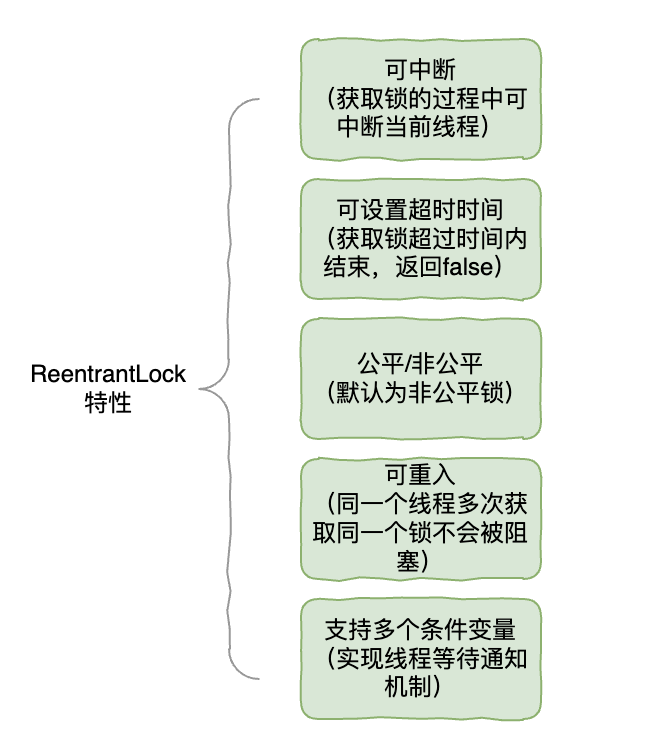
下面我们再来对比看下 ReentrantLock 和 synchronized 的区别:
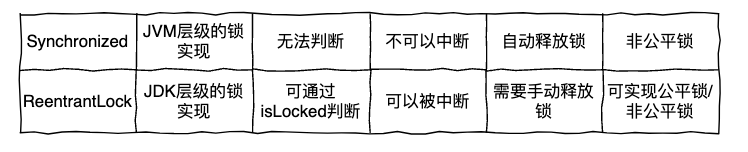
从这些对比就能看出 ReentrantLock 使用更加的灵活,特性更加丰富。
ReentrantLock 是一个悲观锁,即是同一个时刻,只允许一个线程访问代码块,这一点 synchronized 其实也一样。
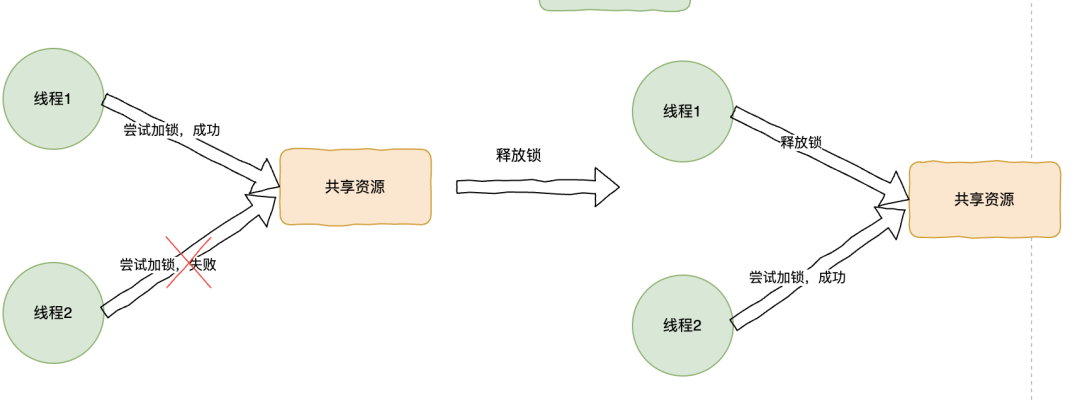
有一些读多写少的场景中比如缓存,大部分时间都是读操作,这里每个操作都要加锁,读性能不是很差吗,有没有更好的方案实现这种场景呀?
当然有的,比如 ReentrantReadWriteLock,读写锁。
针对上述场景,Java 提供了读写锁 ReentrantReadWriteLock,它的内部维护了一对相关的锁,一个用于只读操作,称为读锁;一个用于写入操作,称为写锁。
/** Inner class providing readlock */
private final ReentrantReadWriteLock.ReadLock readerLock;
/** Inner class providing writelock */
private final ReentrantReadWriteLock.WriteLock writerLock;
/** Performs all synchronization mechanics */
final Sync sync;
使用核心代码如下:
public class LocalCacheService {
static Map<String, Object> localCache = new HashMap<>();
static ReentrantReadWriteLock lock = new ReentrantReadWriteLock();
static Lock readL = lock.readLock();
static Lock writeL = lock.writeLock();
public static Object read(String key) {
readL.lock();
try {
return localCache.get(key);
} finally {
readL.unlock();
}
}
public static Object save(String key, String value) {
writeL.lock();
try {
return localCache.put(key, value);
} finally {
writeL.unlock();
}
}
}
在 ReentrantReadWriteLock 中,多个线程可以同时读取一个共享资源。
当有其他线程的写锁时,读线程会被阻塞,反之一样。
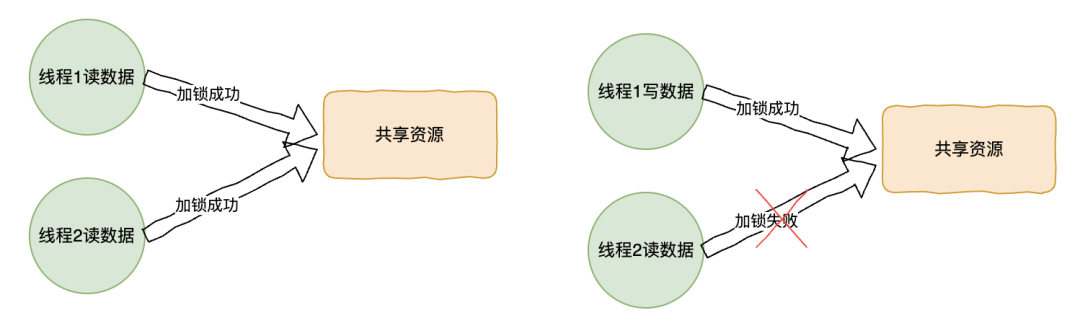
读写锁设计思路
这里有一个关键点,就是在 ReentrantLock 中,使用 AQS 的 state 表示同步状态,表示锁被一个线程重复获取的次数。但是在读写锁 ReentrantReadWriteLock 中,如何用一个变量维护这两个状态呢?
实际 ReentrantReadWriteLock 采用“高低位切割”的方式来维护,将 state 切分为两部分:高 16 位表示读;低 16 位表示写。
分割之后,通过位运算,假设当前状态为 S,那么:
- 写状态=S&0x0000FFFF(将高 16 位全部移除),当写状态需要加 1,S+1 再运算即可。
- 读状态=S>>>16(无符号补 0 右移 16 位),当读状态需要加 1,计算 S+(1<<16)。

MySQL如何与Redis保持数据一致性
- 明确目标:在业务可接受的一致性级别(最终一致/强一致)与性能之间做取舍;缓存只做旁路缓存,写操作以MySQL 为准,Redis 仅用于加速读。
- 标准做法:采用Cache-Aside(旁路缓存)+ 先更新数据库、再删除缓存,并为所有热点 key 设置合理的过期时间(TTL),保证兜底的最终一致性。
- 并发优化:在高频写或强实时场景,叠加延迟双删(写前后各删一次,中间休眠一个“读+写回”的估算窗口)以降低脏数据窗口。
- 异步兜底:引入MySQL binlog + MQ + 消费者回写 Redis,实现解耦与近实时同步,减少人工维护成本。
- 工程要点:写删操作要做幂等、失败要重试;对同一 key 的并发写使用分布式锁(仅在必要时、且尽量缩短持锁时间);监控延迟与不一致告警,定期校对与修复
延迟双删模板
• 伪代码
• del(key)
• updateDB(data)
• Thread.sleep(估计的“读+回填”时间,如500ms~1s,按业务实测调优)
• del(key)
• 作用:清理读线程可能写回的旧值;配合 TTL 作为兜底。
微服务
Eureka 注册中心
Eureka能够自动注册并发现微服务,然后对服务的状态、信息进行集中管理,这样当我们需要获取其他服务的信息时,我们只需要向Eureka进行查询就可以了。
LoadBalancer 负载均衡
在添加
@LoadBalanced注解之后,会启用拦截器对我们发起的服务调用请求进行拦截(注意这里是针对我们发起的请求进行拦截),叫做LoadBalancerInterceptor,它实现ClientHttpRequestInterceptor接口.在进行负载均衡的时候,会向Eureka发起请求,选择一个可用的对应服务,然后会返回此服务的主机地址等信息.
自定义负载均衡策略:
LoadBalancer默认提供了两种负载均衡策略:
RandomLoadBalancer- 随机分配策略- (默认)
RoundRobinLoadBalancer- 轮询分配策略
现在我们希望修改默认的负载均衡策略,可以进行指定,比如我们现在希望用户服务采用随机分配策略,我们需要先创建随机分配策略的配置类(不用加@Configuration):
public class LoadBalancerConfig {
//将官方提供的 RandomLoadBalancer 注册为Bean
@Bean
public ReactorLoadBalancer<ServiceInstance> randomLoadBalancer(Environment environment, LoadBalancerClientFactory loadBalancerClientFactory){
String name = environment.getProperty(LoadBalancerClientFactory.PROPERTY_NAME);
return new RandomLoadBalancer(loadBalancerClientFactory.getLazyProvider(name, ServiceInstanceListSupplier.class), name);
}
}
接着我们需要为对应的服务指定负载均衡策略,直接使用注解即可:
@Configuration
@LoadBalancerClient(value = "userservice", //指定为 userservice 服务,只要是调用此服务都会使用我们指定的策略
configuration = LoadBalancerConfig.class) //指定我们刚刚定义好的配置类
public class BeanConfig {
@Bean
@LoadBalanced
RestTemplate template(){
return new RestTemplate();
}
}
OpenFeign 实现负载均衡
Feign和RestTemplate一样,也是HTTP客户端请求工具,但是它的使用方式更加便捷。首先是依赖:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
</dependency>
接着在启动类添加@EnableFeignClients注解:
@SpringBootApplication
@EnableFeignClients
public class BorrowApplication {
public static void main(String[] args) {
SpringApplication.run(BorrowApplication.class, args);
}
}
那么现在我们需要调用其他微服务提供的接口,该怎么做呢?我们直接创建一个对应服务的接口类即可:
@FeignClient("userservice") //声明为userservice服务的HTTP请求客户端
public interface UserClient {
}
接着我们直接创建所需类型的方法,比如我们之前的:
RestTemplate template = new RestTemplate();
User user = template.getForObject("http://userservice/user/"+uid, User.class);
现在可以直接写成这样:
@FeignClient("userservice")
public interface UserClient {
//路径保证和其他微服务提供的一致即可
@RequestMapping("/user/{uid}")
User getUserById(@PathVariable("uid") int uid); //参数和返回值也保持一致
}
接着我们直接注入使用(有Mybatis那味了):
@Resource
UserClient userClient;
@Override
public UserBorrowDetail getUserBorrowDetailByUid(int uid) {
List<Borrow> borrow = mapper.getBorrowsByUid(uid);
User user = userClient.getUserById(uid);
//这里不用再写IP,直接写服务名称bookservice
List<Book> bookList = borrow
.stream()
.map(b -> template.getForObject("http://bookservice/book/"+b.getBid(), Book.class))
.collect(Collectors.toList());
return new UserBorrowDetail(user, bookList);
}
Hystrix 服务熔断
- 服务降级:服务降级并不会直接返回错误,而是可以提供一个补救措施,正常响应给请求者。这样相当于服务依然可用,但是服务能力肯定是下降了的。
- 服务熔断:熔断机制是应对雪崩效应的一种微服务链路保护机制,当检测出链路的某个微服务不可用或者响应时间太长时,会进行服务的降级,进而熔断该节点微服务的调用,快速返回”错误”的响应信息。当检测到该节点微服务响应正常后恢复调用链路。
实际上,熔断就是在降级的基础上进一步升级形成的,也就是说,在一段时间内多次调用失败,那么就直接升级为熔断。
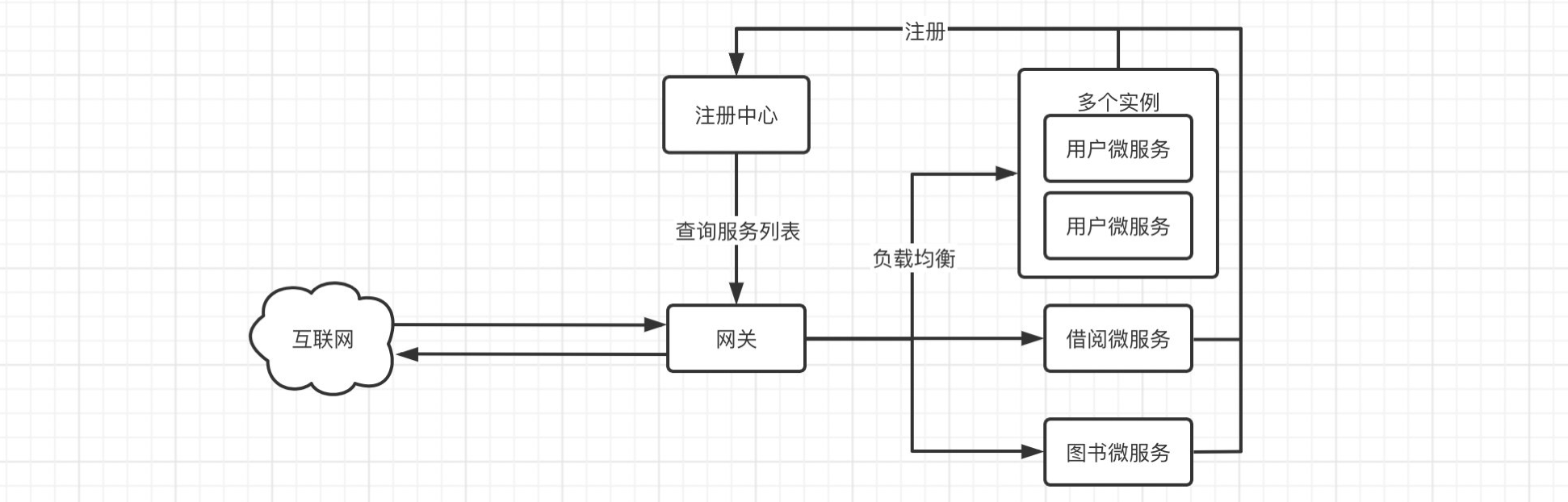
GateWay 路由网关
一般情况下,可能并不是所有的微服务都需要直接暴露给外部调用,这时我们就可以使用路由机制,添加一层防护,让所有的请求全部通过路由来转发到各个微服务,并且转发给多个相同微服务实例也可以实现负载均衡。
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-gateway</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
</dependencies>
路由过滤器
路由过滤器支持以某种方式修改传入的 HTTP 请求或传出的 HTTP 响应,路由过滤器的范围是某一个路由,跟之前的断言一样,Spring Cloud Gateway 也包含许多内置的路由过滤器工厂,详细列表:
https://docs.spring.io/spring-cloud-gateway/docs/current/reference/html/#gatewayfilter-factories
比如我们现在希望在请求到达时,在请求头中添加一些信息再转发给我们的服务,那么这个时候就可以使用路由过滤器来完成,我们只需要对配置文件进行修改:
spring:
application:
name: gateway
cloud:
gateway:
routes:
- id: borrow-service
uri: lb://borrowservice
predicates:
- Path=/borrow/**
# 继续添加新的路由配置,这里就以书籍管理服务为例
# 注意-要对齐routes:
- id: book-service
uri: lb://bookservice
predicates:
- Path=/book/**
filters: # 添加过滤器
- AddRequestHeader=Test, HelloWorld!
# AddRequestHeader 就是添加请求头信息,其他工厂请查阅官网
除了针对于某一个路由配置过滤器之外,我们也可以自定义全局过滤器,它能够作用于全局。但是我们需要通过代码的方式进行编写,比如我们要实现拦截没有携带指定请求参数的请求:
@Component //需要注册为Bean
public class TestFilter implements GlobalFilter {
@Override
public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) { //只需要实现此方法
return null;
}
}
接着我们编写判断:
@Override
public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {
//先获取ServerHttpRequest对象,注意不是HttpServletRequest
ServerHttpRequest request = exchange.getRequest();
//打印一下所有的请求参数
System.out.println(request.getQueryParams());
//判断是否包含test参数,且参数值为1
List<String> value = request.getQueryParams().get("test");
if(value != null && value.contains("1")) {
//将ServerWebExchange向过滤链的下一级传递(跟JavaWeb中介绍的过滤器其实是差不多的)
return chain.filter(exchange);
}else {
//直接在这里不再向下传递,然后返回响应
return exchange.getResponse().setComplete();
}
}
当然,过滤器肯定是可以存在很多个的,所以我们可以手动指定过滤器之间的顺序:
@Component
public class TestFilter implements GlobalFilter, Ordered { //实现Ordered接口
@Override
public int getOrder() {
return 0;
}
注意Order的值越小优先级越高,并且无论是在配置文件中编写的单个路由过滤器还是全局路由过滤器,都会受到Order值影响(单个路由的过滤器Order值按从上往下的顺序从1开始递增),最终是按照Order值决定哪个过滤器优先执行,当Order值一样时 全局路由过滤器执行 优于 单独的路由过滤器执行。
Config 配置中心
Spring Cloud Config 为分布式系统中的外部配置提供服务器端和客户端支持。使用 Config Server,您可以集中管理所有环境中应用程序的外部配置
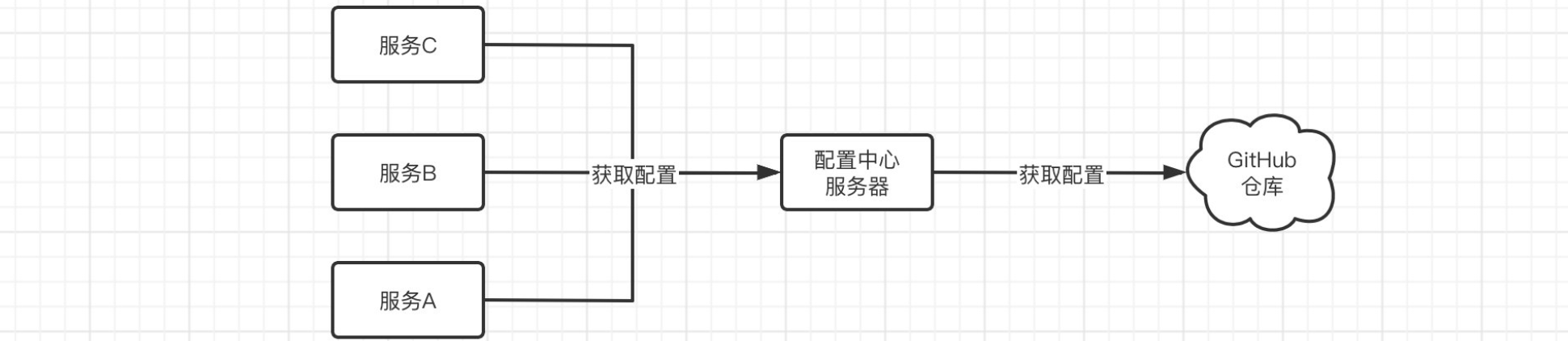
实际上Spring Cloud Config就是一个配置中心,所有的服务都可以从配置中心取出配置,而配置中心又可以从GitHub远程仓库中获取云端的配置文件,这样我们只需要修改GitHub中的配置即可对所有的服务进行配置管理了。
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-config-server</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
</dependencies>
SpringCloud Alibaba
前面我们了解了微服务的一套解决方案,但是它是基于Netflix的解决方案,实际上我们发现,很多框架都已经停止维护了,来看看目前我们所认识到的SpringCloud各大组件的维护情况:
- 注册中心: Eureka(属于Netflix,2.x版本不再开源,1.x版本仍在更新)
- 服务调用: Ribbon(属于Netflix,停止更新,已经彻底被移除)、
SpringCloud Loadbalancer(属于*SpringCloud*官方,目前的默认方案) - 服务降级:
Hystrix(属于Netflix,停止更新,已经彻底被移除) - 路由网关:
Zuul(属于Netflix,停止更新,已经彻底被移除)、Gateway(属于*SpringCloud*官方,推荐方案) - 配置中心: Config(属于*
SpringCloud*官方)
可见,我们之前使用的整套解决方案中,超过半数的组件都已经处于不可用状态,并且部分组件都是SpringCloud官方出手提供框架进行解决,因此,寻找一套更好的解决方案势在必行,也就引出了我们本章的主角:SpringCloud Alibaba
目前 Spring Cloud Alibaba 提供了如下功能:
- 服务限流降级:支持
WebServlet、WebFlux,OpenFeign、RestTemplate、Dubbo 限流降级功能的接入,可以在运行时通过控制台实时修改限流降级规则,还支持查看限流降级 Metrics 监控。 - 服务注册与发现:适配 Spring Cloud 服务注册与发现标准,默认集成了 Ribbon 的支持。
- 分布式配置管理:支持分布式系统中的外部化配置,配置更改时自动刷新。
- Rpc服务:扩展 Spring Cloud 客户端
RestTemplate和OpenFeign,支持调用 Dubbo RPC 服务 - 消息驱动能力:基于 Spring Cloud Stream 为微服务应用构建消息驱动能力。
- 分布式事务:使用
@GlobalTransactional注解, 高效并且对业务零侵入地解决分布式事务问题。 - 阿里云对象存储:阿里云提供的海量、安全、低成本、高可靠的云存储服务。支持在任何应用、任何时间、任何地点存储和访问任意类型的数据。
- 分布式任务调度:提供秒级、精准、高可靠、高可用的定时(基于 Cron 表达式)任务调度服务。同时提供分布式的任务执行模型,如网格任务。网格任务支持海量子任务均匀分配到所有 Worker(
schedulerx-client)上执行。 - 阿里云短信服务:覆盖全球的短信服务,友好、高效、智能的互联化通讯能力,帮助企业迅速搭建客户触达通道。
可以看到,SpringCloudAlibaba实际上是对我们的SpringCloud组件增强功能,是SpringCloud的增强框架,可以兼容SpringCloud原生组件和SpringCloudAlibaba的组件
Nacos 更加全能的注册中心
Nacos(Naming Configuration Service)是一款阿里巴巴开源的服务注册与发现、配置管理的组件,相当于是Eureka+Config的组合形态。
服务注册与发现
要实现基于Nacos的服务注册与发现,那么就需要导入SpringCloudAlibaba相关的依赖,我们在父工程将依赖进行管理:
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>2.2.0</version>
</dependency>
<!-- 这里引入最新的SpringCloud依赖 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>2021.0.1</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<!-- 这里引入最新的SpringCloudAlibaba依赖,2021.0.1.0版本支持SpringBoot2.6.X -->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-alibaba-dependencies</artifactId>
<version>2021.0.1.0</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
接着我们就可以在子项目中添加服务发现依赖了,比如我们以图书服务为例:
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>
和注册到Eureka一样,我们也需要在配置文件中配置Nacos注册中心的地址:
server:
# 之后所有的图书服务节点就81XX端口
port: 8101
spring:
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://cloudstudy.mysql.cn-chengdu.rds.aliyuncs.com:3306/cloudstudy
username: test
password: 123456
# 应用名称 bookservice
application:
name: bookservice
cloud:
nacos:
discovery:
# 配置Nacos注册中心地址
server-addr: localhost:8848
接着我们使用OpenFeign,实现服务发现远程调用以及负载均衡,导入依赖:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
</dependency>
<!-- 这里需要单独导入LoadBalancer依赖 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-loadbalancer</artifactId>
</dependency>
编写接口:
@FeignClient("userservice")
public interface UserClient {
@RequestMapping("/user/{uid}")
User getUserById(@PathVariable("uid") int uid);
}
@FeignClient("bookservice")
public interface BookClient {
@RequestMapping("/book/{bid}")
Book getBookById(@PathVariable("bid") int bid);
}
@Service
public class BorrowServiceImpl implements BorrowService{
@Resource
BorrowMapper mapper;
@Resource
UserClient userClient;
@Resource
BookClient bookClient;
@Override
public UserBorrowDetail getUserBorrowDetailByUid(int uid) {
List<Borrow> borrow = mapper.getBorrowsByUid(uid);
User user = userClient.getUserById(uid);
List<Book> bookList = borrow
.stream()
.map(b -> bookClient.getBookById(b.getBid()))
.collect(Collectors.toList());
return new UserBorrowDetail(user, bookList);
}
}
@EnableFeignClients
@SpringBootApplication
public class BorrowApplication {
public static void main(String[] args) {
SpringApplication.run(BorrowApplication.class, args);
}
}
值得注意的是,Nacos区分了临时实例和非临时实例:
那么临时和非临时有什么区别呢?
- 临时实例:和Eureka一样,采用心跳机制向
Nacos发送请求保持在线状态,一旦心跳停止,代表实例下线,不保留实例信息。 - 非临时实例:由
Nacos主动进行联系,如果连接失败,那么不会移除实例信息,而是将健康状态设定为false,相当于会对某个实例状态持续地进行监控。
我们可以通过配置文件进行修改临时实例:
spring:
application:
name: borrowservice
cloud:
nacos:
discovery:
server-addr: localhost:8848
# 将ephemeral修改为false,表示非临时实例
ephemeral: false
如果这时我们关闭此实例,只是将健康状态变为false,而不会删除实例的信息。
集群分区
要提供Nacos的负载均衡实现才能开启区域优先调用机制,只需要在配制文件中进行修改即可:
spring:
application:
name: borrowservice
cloud:
nacos:
discovery:
server-addr: localhost:8848
cluster-name: Chengdu
# 将loadbalancer的nacos支持开启,集成Nacos负载均衡
loadbalancer:
nacos:
enabled: true
除了根据区域优先调用之外,同一个区域内的实例也可以单独设置权重,Nacos会优先选择权重更大的实例进行调用,我们可以直接在管理页面中进行配置:
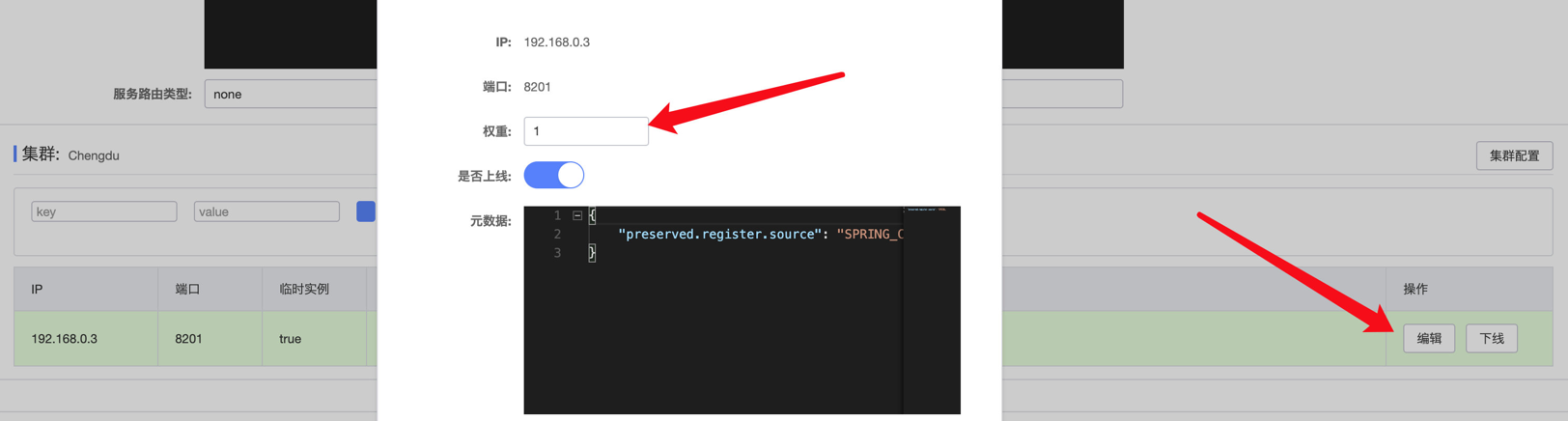
或是在配置文件中进行配置:
spring:
application:
name: borrowservice
cloud:
nacos:
discovery:
server-addr: localhost:8848
cluster-name: Chengdu
# 权重大小,越大越优先调用,默认为1
weight: 0.5
通过配置权重,某些性能不太好的机器就能够更少地被使用,而更多的使用那些网络良好性能更高的主机上的实例。
配置中心
将借阅服务的配置文件放到Nacos进行管理,那么这个时候就需要在Nacos中创建配置文件:

将借阅服务的配置文件全部(当然正常情况下是不会全部CV的,只会复制那些需要经常修改的部分,这里为了省事就直接全部CV了)复制过来,注意Data ID的格式跟我们之前一样,应用名称-环境.yml,如果只编写应用名称,那么代表此配置文件无论在什么环境下都会使用,然后每个配置文件都可以进行分组,也算是一种分类方式:
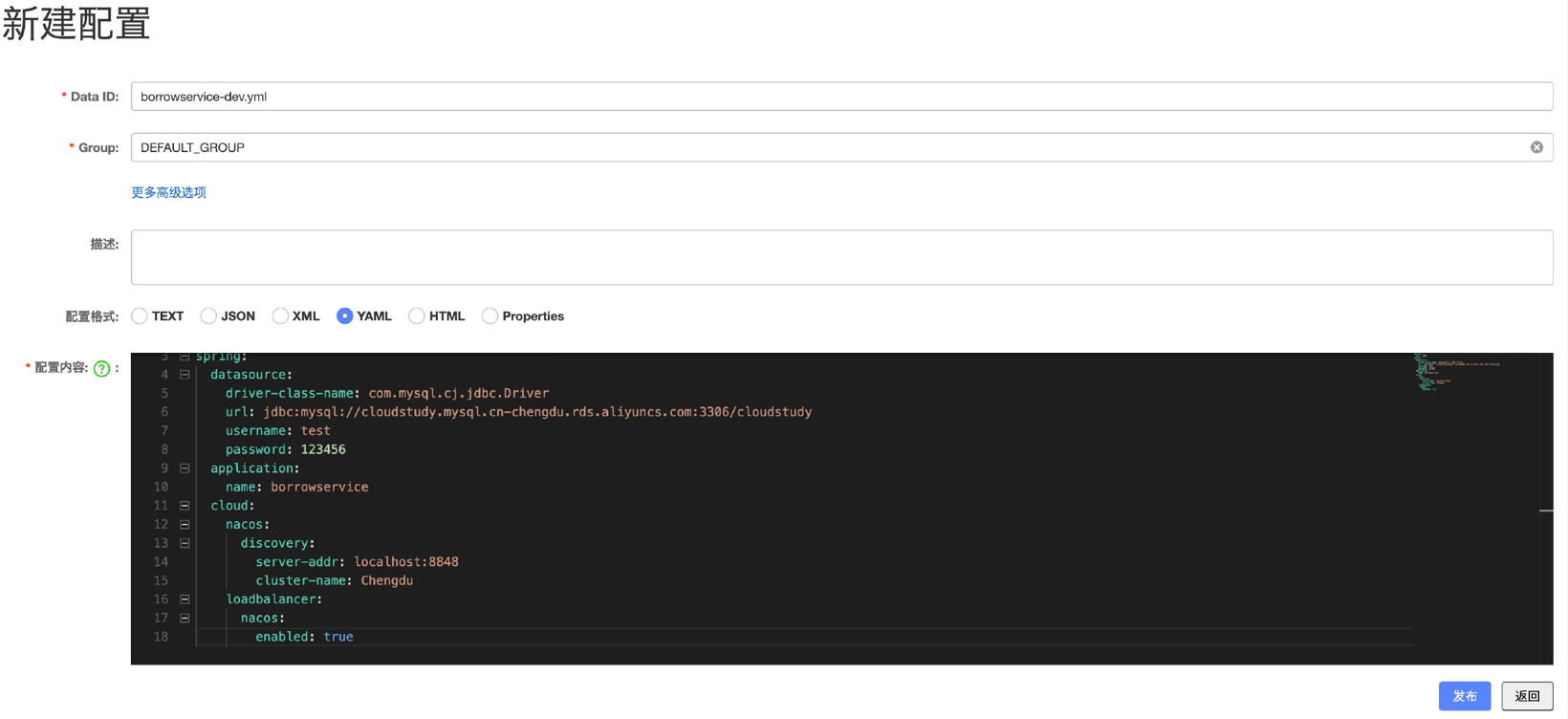
完成之后点击发布即可:

然后在项目中导入依赖:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-bootstrap</artifactId>
</dependency>
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId>
</dependency>
接着我们在借阅服务中添加bootstrap.yml文件:
spring:
application:
# 服务名称和配置文件保持一致
name: borrowservice
profiles:
# 环境也是和配置文件保持一致
active: dev
cloud:
nacos:
config:
# 配置文件后缀名
file-extension: yml
# 配置中心服务器地址,也就是Nacos地址
server-addr: localhost:8848
Nacos还支持配置文件的热更新,比如我们在配置文件中添加了一个属性,而这个时候可能需要实时修改,并在后端实时更新,那么这种该怎么实现呢?我们创建一个新的Controller:
@RestController
public class TestController {
@Value("${test.txt}") //我们从配置文件中读取test.txt的字符串值,作为test接口的返回值
String txt;
@RequestMapping("/test")
public String test(){
return txt;
}
}
我们修改一下配置文件,然后重启服务器:
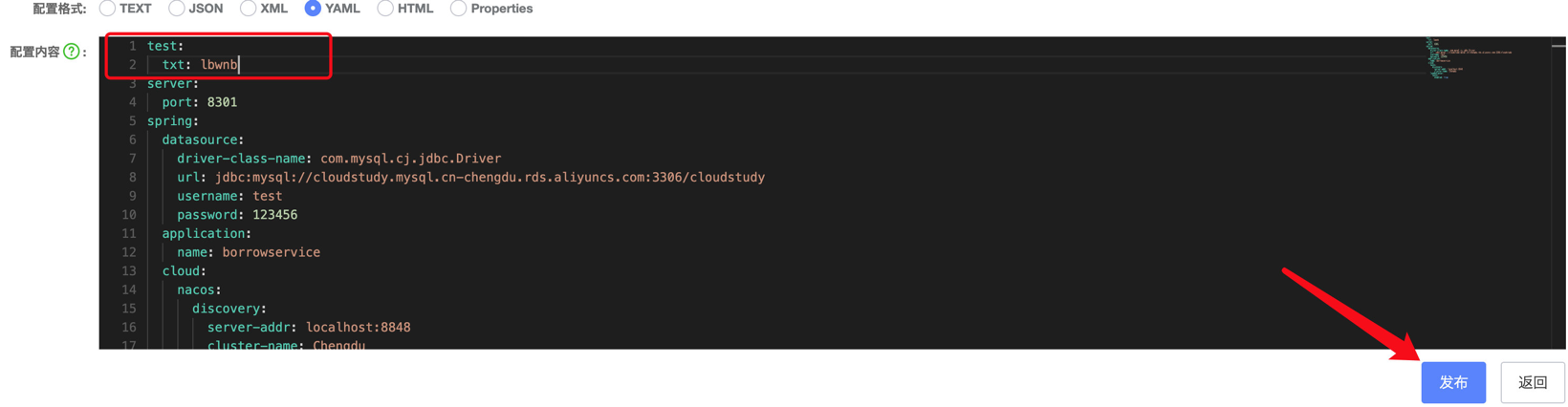
可以看到已经可以正常读取了:

那么如何才能实现配置热更新呢?我们可以像下面这样:
@RestController
@RefreshScope //添加此注解就能实现自动刷新了
public class TestController {
@Value("${test.txt}")
String txt;
@RequestMapping("/test")
public String test(){
return txt;
}
}
重启服务器,再次重复上述实验,成功。
命名空间
Sentinel 流量防卫兵
Seata 与 分布式事务
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 jungle8884@163.com

